
Simulate the 4 Percent Rule for Retirement with Python
 When it comes to planning for retirement, the 4% rule is considered the sacred rule for withdrawal. It essentially states, that given a diversified portfolio, a retiree can safely withdraw 4% from their retirement nest egg every year in retirement (a 30-year retirement is assumed).
When it comes to planning for retirement, the 4% rule is considered the sacred rule for withdrawal. It essentially states, that given a diversified portfolio, a retiree can safely withdraw 4% from their retirement nest egg every year in retirement (a 30-year retirement is assumed).
In this article I will cover how to construct a simulation with the 4% rule for retirement as the premise in Python. Within the code you can adjust your own planning considerations and plot out your expected returns based on the random assignment of historical stock market returns over a defined period.
Note: I will be assuming a portfolio constructed of 100% Stocks (vs a 60% Stock and 40% Bond mix)… however this is easily modifiable.
You will need to have access to a Python environment either on your computer or in the cloud. If you would like more information on the 4% Rule so you can better follow the Python code then you can check out this article I wrote on the topic for a quick primer.
Below is what we will cover in this article.
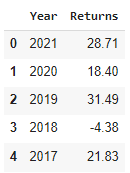
Creating a Function for Investment Returns: Pre-Retirement
In order to calculate and store the simulation data (e.g., each year’s returns on principal and withdrawal amounts) we will be executing the same few lines of code repeatedly. Thus, for this exercise I will create a function to handle everything with as little code as necessary.
But first let’s look at the components of what will constitute our new function. Essentially, two for loops will be used. The first loop will calculate the growth of the principal while the portfolio has active contributions (during working years). This code can be seen below.
Last year’s interest is multiplied by a value found randomly in our random_return DataFrame and then the yearly contribution is added and stored as the current year’s principal. No withdrawal or distribution is subtracted since the portfolio hasn’t reached retirement mode yet.
Creating a Function for Investment Returns: Putting it All Together
Below we actually create our function and name it retire4. By calling and running this function with the required arguments (the initial 4 variables we defined earlier) it will return a DataFrame with the same columns as above.
Plotting Our Results for a Single Result
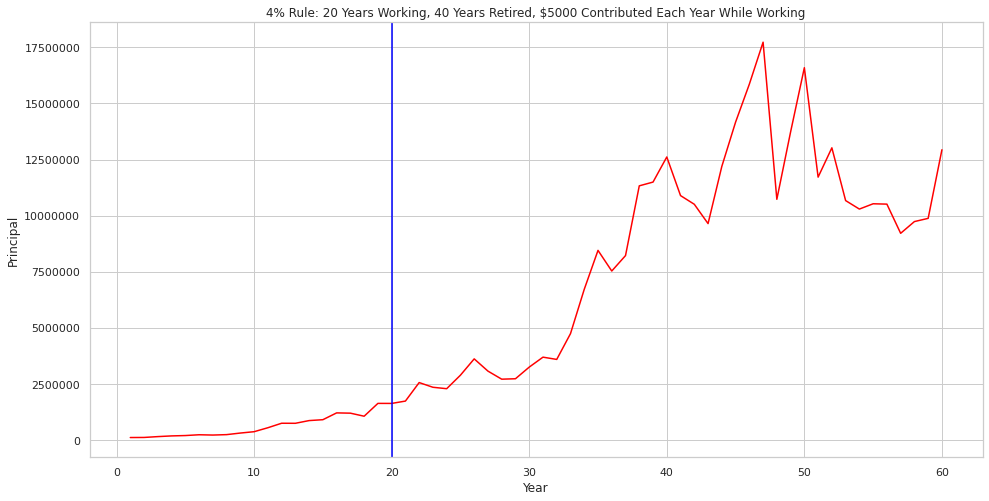
Now it’s time to see what a single trial of our simulation looks like when plotted out. Using MatPlotLib and Seaborn we can quickly plot out the results of data2.
I plotted a blue vertical line to denote the transition from working to retired. This also shows when contributions stop, and withdrawals start.
Given the long time period of the plot (60 years in this case), volatility seems to substantially increase during the later years, but this is just due to working with larger principals that have compounded for long periods.
By eventually plotting out large numbers of trials we should be able to smooth out the variability during later years of retirement.
Simulating Retirement Outcomes Across 10 Trials
Now let’s simulate the results for 10 trials. To do this I will create a new DataFrame called simulation and simply call our previously created retire4 function 10 times in a for loop.
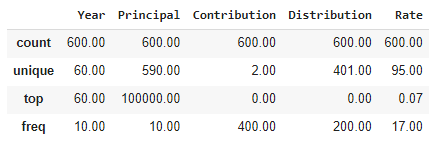
Plotting Retirement Outcomes Across 10 Trials
Now that we have generated the data, plotting out our 10-run simulation is simple. Seaborn will automatically plot a line for the mean and highlight the range of the Standard Deviation that bounds the mean line.
As should be expected, the variability once again at the end of the 60-year period is significant. This should not be a cause for alarm. The large number of random outcomes possible is what creates this wide channel.
From this simulation it does appear that the 4% rule is a safe withdrawal rate. It does not look like that the principal is ever at risk of being depleted.
But what does the 4% withdrawal amount actually look like? Is it enough to live on? I’ll cover that next.
Plotting Annual Distributions at 4% for 10 Trials
Plotting out the annual distributions or withdrawals for the 10-run simulation only requires a variable change in the code below. I changed the colors as well to help highlight the different interpretation of the plot.

As you can see above, the withdrawal rate does deviate from year to year but on average, it does generally go up. Keep in mind that this does not include the effects of inflation, however, the 4% Rule tackles this by assuming your portfolio grows enough each year to make up for this shortfall.
Simulating Retirement Outcomes Across 100 Trials
Now let’s see how running 100 trials changes things. Theoretically, our Standard Deviation depicted by the light red and green channels will narrow as we run more trials.
This narrowing doesn’t necessarily give us better information on how our portfolio will perform, but it will highlight the long-term uptrend of the Stock Market.

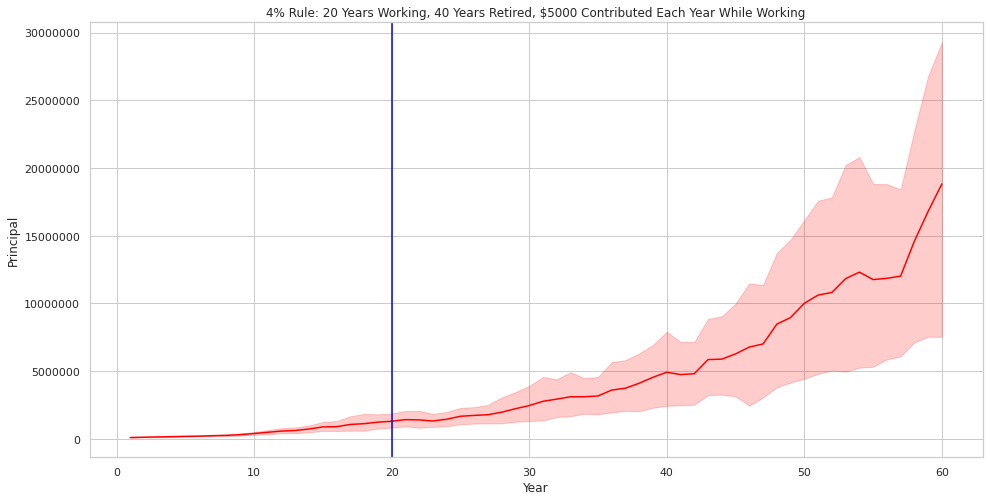
Plotting Retirement Outcomes Across 100 Trials
Below is the resulting plot of the principal. It frankly looks very similar to the 10 Trial plot with the exception that the channel is narrow, and the mean line is smoothed.
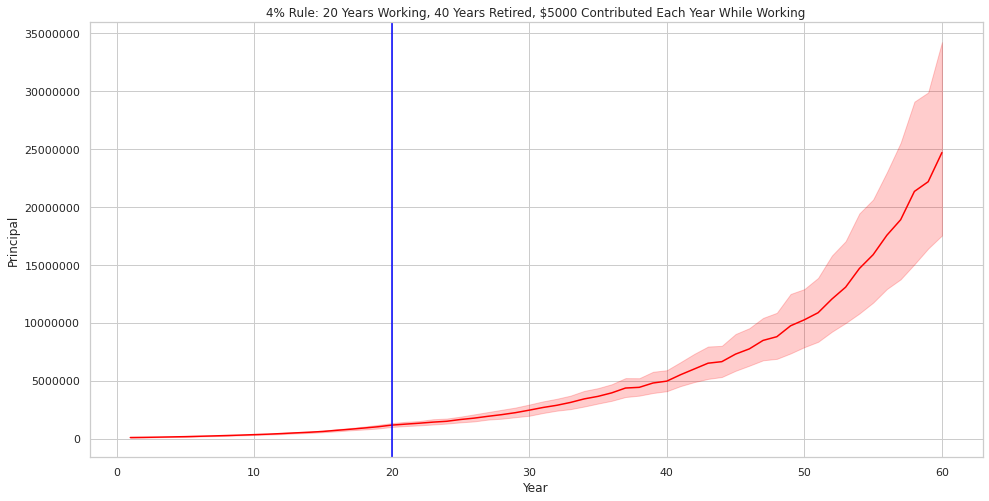
Plotting Annual Distributions at 4% for 100 Trials
Plotting out the withdrawals and distributions at 4% also results in a similiar smoother / narrower version of the 10 Trial simulation. The interpretation, once again, is that a 4% withdrawal rate seems to work just fine with a 100% Stock Portfolio over a long time horizon.
It should be also noted that this simulation assumes that the next 100 years in the Stock Market looks similar to the past 100 years. Smart folks out there would tell you that past performance doesn’t guarantee future results… buyer beware.
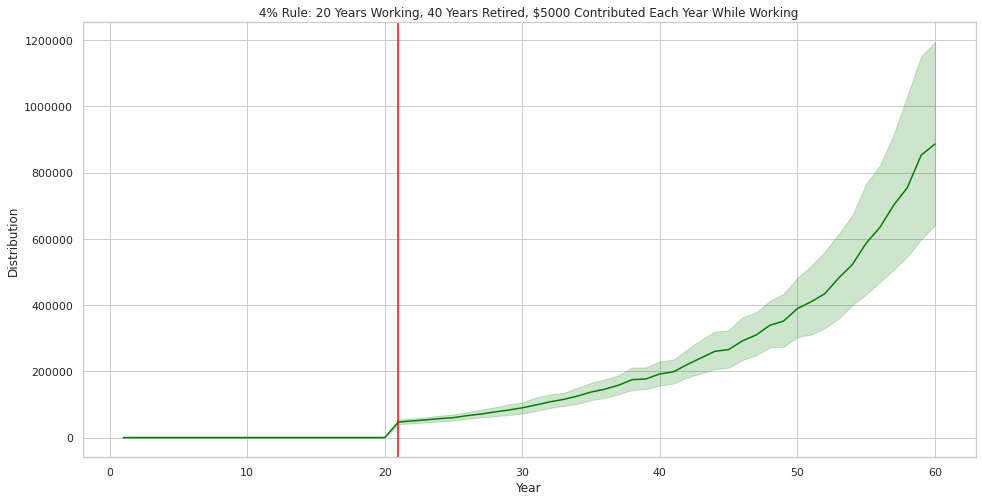
Calculating the 4% Rule Simulation Descriptive Statistics
Now that we’ve crunched the numbers and ran our simulation let’s see what the plots are telling us in a more specific fashion. Below you will find that on average you would be able to withdraw $46,820.95 during your first year of retirement. The standard deviation is significant at $36,396.

Below you can see that during the final year of retirement you can, on average, expect to withdraw $886,202.75. This may seem like a lot, but it would be helpful to consider inflation in this scenario.
After 60 years, if inflation compounds at 3% then $1.00 of spending power today would require $5.89 in the future. This means that $886,202.75 would have spending power of about $150,000 in today’s dollars.

Below, you will see that on average you could expect to have $1.2 Million of principal during the first year of retirement.

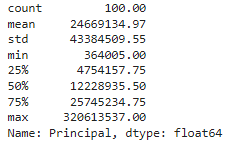
And, at the end of retirement you could expect, on average, to have about $24.7 Million. That is the incredible power of compounding returns!
Additional Considerations for Simulation
This is a great ‘first step’ simulation to get an idea if using the 4% rule for retirement withdrawals makes sense. Here are a few ideas and warnings on where to take the ideas presented in this article:
It would be easy to modify the function we created to run simulations for other percentages such as 3%, 3.5% or even 4.5% and 5%.
As mentioned previously, prior Stock Market performance does not predict future returns. Modifying the pool of returns for random assignment based on a more sophisticated outlook could substantially change the result of the simulation.
More trials does not necessarily mean more confidence in outcome. In fact, the more trials you run you will likely smooth out a few trials that could highlight problems with your investment approach. The right sequence of poor returns combined with withdrawals could be devastating and be missed if you just look at the scenario mean and standard deviation.
Inflation is generally considered ‘taken care of’ when using the 4% rule… thus, interpreting the final principal and withdrawal amounts need context. It does appear from our simulation that over the long term the spending power of a retiree may go up, however.
Final Thoughts
I hope you enjoyed this article! If you have any other thoughts about how to make the simulation better or ideas on how to better communicate the results be sure to throw them in the comments below!


