
Simulate Dollar Cost Averaging with Python
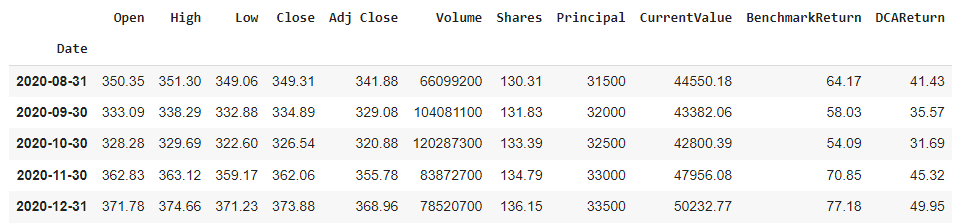
Below is a screen shot of the resulting DataFrame returned by yfinance. The date is set as the index. The column we will be most interested in is the ‘Adj Close’ field… not ‘close.’ The adjusted close considers dividends and any type of stock splits that may distort the pricing data over time.
By using this field, we will also be assuming that any dividends earned will be reinvested. This is an important distinction in that dividends can return several hundred basis points a year. When compounded they can drastically impact the final balance.

Dollar Cost Averaging Parameters
Next, we need to define the parameters of our Dollar Cost Averaging exercise. Much like the Compound Interest Calculator I created in Python, we need to establish the starting principal and the reoccurring monthly contribution. Those variables are set below.
Additionally, the starting and ending month and years are set. The reason I decided to use integers instead of a date typed variable is to make the code as accessible as possible. There are certainly shorter and more elegant ways to conduct some of this, however the goal here is to make the code completely accessible to beginners.
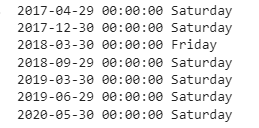
After I calculate the dates, I then store them in a variable called contribution_dates. The output of the first few entries can be seen below.

Removing Weekends and Non-Trading Days
Just contributing your DCA amount at the end of each month sounds simple enough, however, for computational purposes its too simple. The last day of a month may include a weekend, a holiday, or some other non-trading day for which the data set we downloaded will be insufficient.
To account for this I have created a very simple and blunt force approach. If a day in contribution_dates cannot be found in the set of dates downloaded into to data then that date is moved 1 day earlier. If the date is a Sunday then it will be moved to the previous Saturday. This done iteratively until the date matches a trading day within data.
As you will see, I only had to run through this algorithm twice. You may find that given the dates you select and the security chosen you may have to iterate further.

After one round of moving dates to the left the number of records that were not actually trading days drops from 13 down to 7.
Plotting Dollar Cost Averaging Results with Python
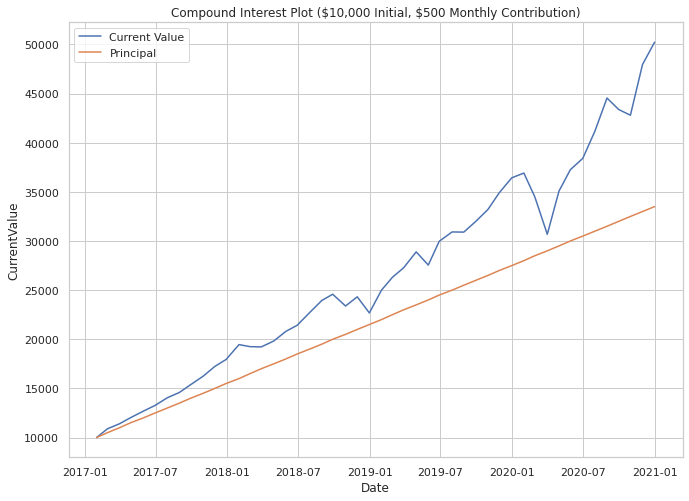
Using the MatPlotLib and Seaborn libraries it is now easy to create a couple of plots that can help us interpret how our DCA simulation performed. In the plot below, I simply plotted the CurrentValue and Principal fields across all contribution dates.
The resulting plot gives a clear depiction of how the returns in SPY helped our fictional investor compound their earnings over time. The disparity between the orange and blue lines gets larger and larger over successive periods. It should be noted that the during the time periods used, the S&P 500 went mostly up… but so does the Stock Market in general over long periods.
If the SPY had been declining over the entire period, we should subsequently expect to have not performed better against the principal.
Comparing Dollar Cost Averaging and the Benchmark
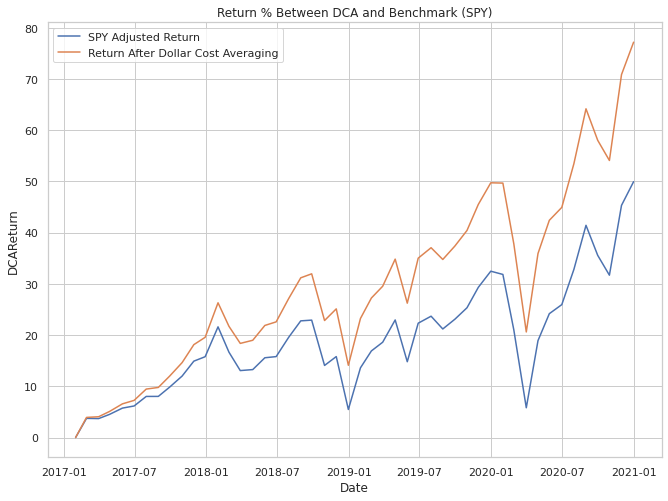
Another interesting plot can be used to verify that what we think has been calculated actually makes sense. Dollar Cost Averaging will result in a higher cost basis over time if the underlying asset is increasing over the entire period. As each successive month rolls on buy, the purchase price of the stock or security goes up.
Given this, if the underlying benchmark is going up in price we should expect our plotted line for our investment to be below that line. This does not mean that DCA has failed, it only helps us verify that what we calculated is in fact what we were expecting.
On the other hand, if you had started investing at a market peak and successively purchased in for a period of time where the price declined you could expect that your performance on a percentage terms outperforms the market. Take a gander below at a comparison of performances based on % terms of the data we have been using:
Summary
In this article I have showed you how to pull in market data for a stock through Yahoo! Finance using python and then simulate how an investment may perform if you utilized Dollar Cost Averaging. Understanding the potential compound growth opportunities in the market can help not only educate but also motivate potential investors.
Additionally, understanding how investment performance differs when using DCA vs a lump sum investment during market extremes may also help those that have suddenly come upon a large windfall of money.
I hope you enjoyed this article! I love getting feedback both positive and constructive so head to the comments section if you have anything you would like to share!


