
Calculate the Stock Market CAGR with Python

What is CAGR and Why Should I Use it?
CAGR is a way of measuring performance by ignoring volatility. I wrote an entire article about the CAGR formula and the nuances of its competitor, the Average Annual Return (AAR). The best way to explain CAGR is by explaining an example using AAR.
With AAR, as its name implies, you just average the annual returns. Take an example portfolio that starts at $100. After the first year it makes 100%, and thus has a value of $200. After the second year it takes a 50% loss… it now finishes the 2 year period at $100. Exactly where it began.
With AAR, the measure of performance would be 25%. That would be the average return over the two years. If I told you that you averaged a 25% return over any period you’d probably be happy… but in this example it resulted in no gain. That’s the flaw of using AAR.
Using CAGR, the following formula would apply:
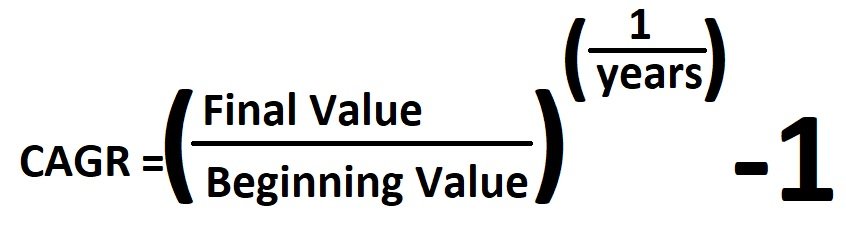
Using this formula, the CAGR for our example would be 0%. This is exactly what we would have rationally expect. Thus, using CAGR as a measure of performance is a great we to compare equities.
Getting Started in Python
Whether you are a beginner at coding in general, or a veteran, using Google Colab to run these quick Python examples is an easy way to test things out. I have a written a quick and short primer on how to get started with Google Colab here.
By using Google Colab, you will be able to run your code in the cloud for free. All you will need is Chrome. Additionally, many of the Python dependencies that can cause headaches for newbies are solved in advance. Just type a few lines of code and execute.
Alternatively, you can use your own Python environment. I personally use Anaconda to help manage my environment but there are an infinite ways to get started. For this article I will be using only a few packages that are readily available on PyPi.
Loading the Necessary Python Packages
The first block of code I wrote is just simply to load the packages. Only 2 packages are used in this short example: numpy and yfinance. numpy is used for the execution of the formula (the power function). yfinance is used to pull the actual stock data into a DataFrame.


